[서울] 서울 강남구 역삼로17길 57 그랜드빌딩
[인천] 인천광역시 연수구 갯벌로 12 미추홀타워 본관 1404호
ALL RIGHTS RESERVED.

M-STT
M-STT
인공지능 기반 음성 인식 솔루션
M-STT(Speech To Text)는 인식된 음성을 실시간으로
정확하게 텍스트로 변환하는 기능을 제공하며, 저장되어 있는
대용량 음성 파일을 한 번에 텍스트로 변환할 수 있습니다.




M-STT의 특징
-

세계 최초 오디오 기반 검색
음성데이터(오디오)에서 바로 검색이 가능한 기능으로
텍스트로 변환되어 있는 데이터가 아니기 때문에
더욱 빠르게 원하는 내용을 검색할 수 있습니다. -

다중화자 구분 가능
타사는 화자 구분 가능 수에 제한이 있지만,
M-STT는 개별 채널 사용 시 무제한으로 화자 구분이 가능합니다. -

시스템 구축 시간과 비용 절감
On Top 형태의 플랫폼 설치로 시스템 구축 시간과 비용을 절감할 수 있습니다.
장점 & 기대효과
-

타임스탬프 제공
각 단어가 인식된 시간과 정확도를 확인할 수 있습니다. 단어와 타임스탬프가 맞지 않을 경우, 수동으로 각 단어와 타임스탬프를 일치시킬 수 있으며 이를 통해 정확도를 개선할 수 있습니다.
-

커스텀 단어사전
고객의 비즈니스에 필요한 단어를 학습시킴으로써 각각의 사업 환경에 적합한 맞춤형 STT 엔진을 제공할 수 있습니다.
-

오픈 API
오픈 API를 통해 확장성 및 유연성을 제공하며 REST API에 기초한 모바일, 웹, 기타 레거시 시스템 연동을 통해 비즈니스 확장성을 보장합니다.
-

On-Premise 또는 Cloud 지원
On-Premise 또는 Cloud를 지원하여 요구사항에 따라 솔루션 도입이 가능합니다. 필요에 따라 구축형으로 설계할 수 있어 고객 민감정보 등 중요 정보 보안 및 관리에 용이합니다.
-

다국어 지원
한국어뿐만 아니라 영어, 스페인어, 불어 등을 실시간으로 지원하고 표준 다국어 외에 지역별로 특성화된 방언 인식 기능을 제공하여 글로벌 사업 환경에 적절합니다.
-

뛰어난 인식률
소음을 포함한 음성 파일이나 시끄러운 환경의 대화에서도 높은 인식률을 보이며 지속적인 학습과 산업별 심화학습으로 타사대비 높은 정확도를 자랑합니다.
적용 예시 & 성공 사례

방송

국제회의

사내회의

그 외 분야
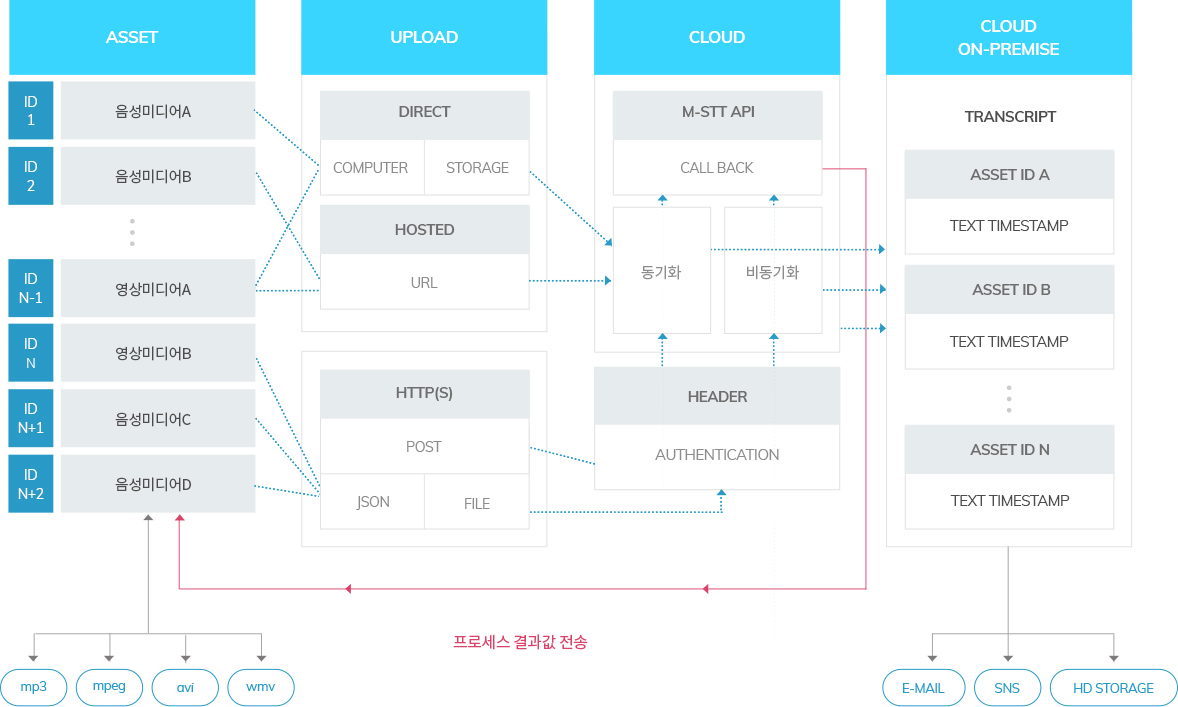
아키텍쳐